

Multi Tier Annotation Search
In recent years, multiple solutions have come available providing search on huge amounts of plain text and metadata. Scalable searchability on annotated text however still appears to be problematic. Using Mtas, we not only take advantage of the strength from Lucene and Solr, but extend queries with CQL conditions on annotated text
[pos="LID"] [pos="ADJ"]? [lemma="amsterdam"]
<entity="location/> within (<s/> containing [lemma="utrecht"])
Also a Simple query parser can be used
koe paard
"de koe" paard
"de pos:ADJ koe"
Parsers for several document formats are provided, each with extended possibilities for configuration.
Advanced query features like statistics, termvectors and kwic are included.
Source code and releases are available on GitHub, see installation instructions on how to get started.
This project builds upon the latest commit from April 30, 2018 for meertensinstituut/mtas. See also the related broker project, another continuation of previous work.
Nederlab
One of the primary use cases for Mtas, the Nederlab project, currently1 provides access, both in terms of metadata and annotated text, to over 74 million items for search and analysis as specified below.
| Total | Mean | Min | Max | |
|---|---|---|---|---|
| Solr index size | 2,715 G | 60.3 G | 75 k | 288 G |
| Solr documents | 74,762,559 | 1,661,390 | 119 | 11,912,415 |
Collections are added and updated regularly by adding new cores, replacing cores and/or merging new cores with existing ones. Currently, the data is divided over 44 separate cores. For 41,437,881 of these documents, annotated text varying in size from 1 to over 3.5 million words is included:
| Total | Mean | Min | Max | |
|---|---|---|---|---|
| Words | 18,494,454,357 | 446 | 1 | 3,537,883 |
| Annotations | 95,921,919,849 | 2,314 | 4 | 23,589,831 |
Middelnederlands
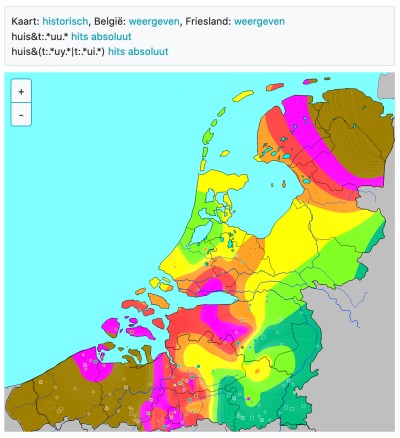
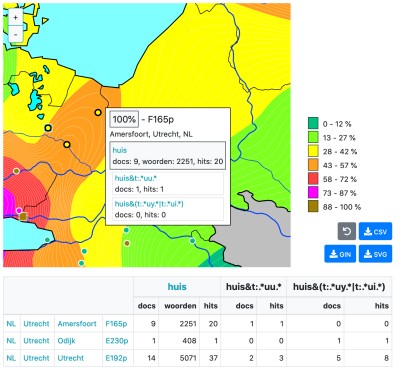
Mtas is also used on Middelnederlands.nl, including geographical selections and new analysis options.2

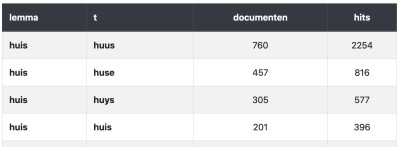
Keyword in context
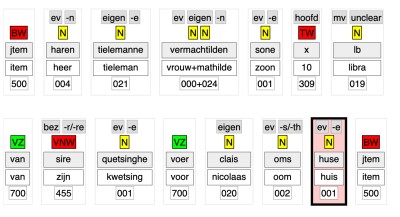
Group results
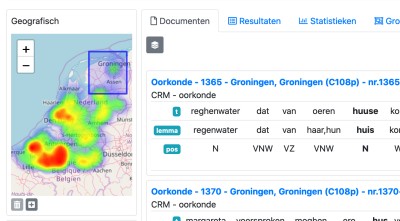
Geographic conditions
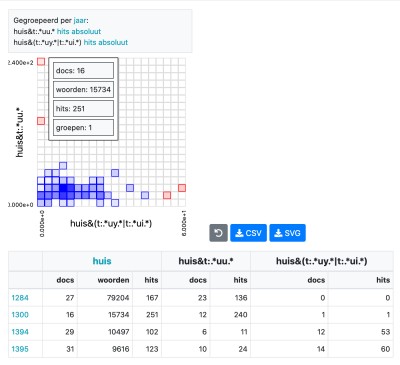
Correlation analysis
Geographical analysis
1 situation June 2018
2 release April 2020